안녕하세요! 데이터 처리, 특히 누적 합(Prefix Sum) 계산과 원소 갱신(Update) 문제로 골머리를 앓아본 적 있으신가요? 배열에서 특정 구간의 합을 구하거나 특정 원소의 값을 변경하는 작업이 빈번할 때, 무식하게 반복문을 돌리면 성능 저하가 눈에 띄게 나타납니다.
이런 상황에서 여러분의 코드를 에서 으로 바꿔줄 마법 같은 자료구조가 있습니다. 바로 Fenwick Tree입니다! (일명 Binary Indexed Tree, BIT라고도 불리죠).
이 글에서는 Fenwick Tree가 무엇인지, 왜 필요한지, 그리고 어떻게 동작하는지 쉽게 알려드릴게요.
Fenwick Tree, 왜 필요한가요?
단순 배열에서 누적 합을 계산하고 원소를 갱신한다고 가정해봅시다.
- 배열 arr에서 arr[0]부터 arr[k]까지의 합을 구하기: 일반적으로 arr[0] + arr[1] + ... + arr[k]를 모두 더해야 합니다. ( 시간 소요)
- arr[i]의 값을 변경하기: 만약 누적 합을 미리 계산해 둔 prefix_sum 배열이 있다면, arr[i]가 변경될 때 prefix_sum[i]부터 prefix_sum[N-1]까지 모든 값을 다시 계산해야 합니다. ( 시간 소요)
이런 작업이 수천, 수만 번 반복된다면 여러분의 프로그램은 거북이가 될 겁니다. Fenwick Tree는 이러한 문제에 대한 빠르고 효율적인 해결책을 제공합니다.
Fenwick Tree (BIT)란 무엇인가요?
Fenwick Tree는 점 갱신(Point Update)과 구간 합 질의(Range Sum Query)를 각각 이라는 놀라운 시간 복잡도로 수행할 수 있게 해주는 특별한 자료구조입니다. 일반적인 배열과 거의 동일한 의 메모리만 사용하며, 세그먼트 트리(Segment Tree)보다 구현이 간단하다는 장점도 가지고 있습니다.
그럼 이 마법 같은 자료구조는 어떻게 작동할까요? 핵심은 이진법과 최하위 비트(LSB)에 있습니다.
LSB(Least Significant Bit)란? 어떤 이진수에서 가장 오른쪽에 있는 '1' 비트가 나타내는 값입니다. 예를 들어:
- : LSB는 입니다.
- : LSB는 입니다.
- : LSB는 입니다. 코드에서는 i & (-i) 연산으로 LSB를 아주 효율적으로 구할 수 있습니다.
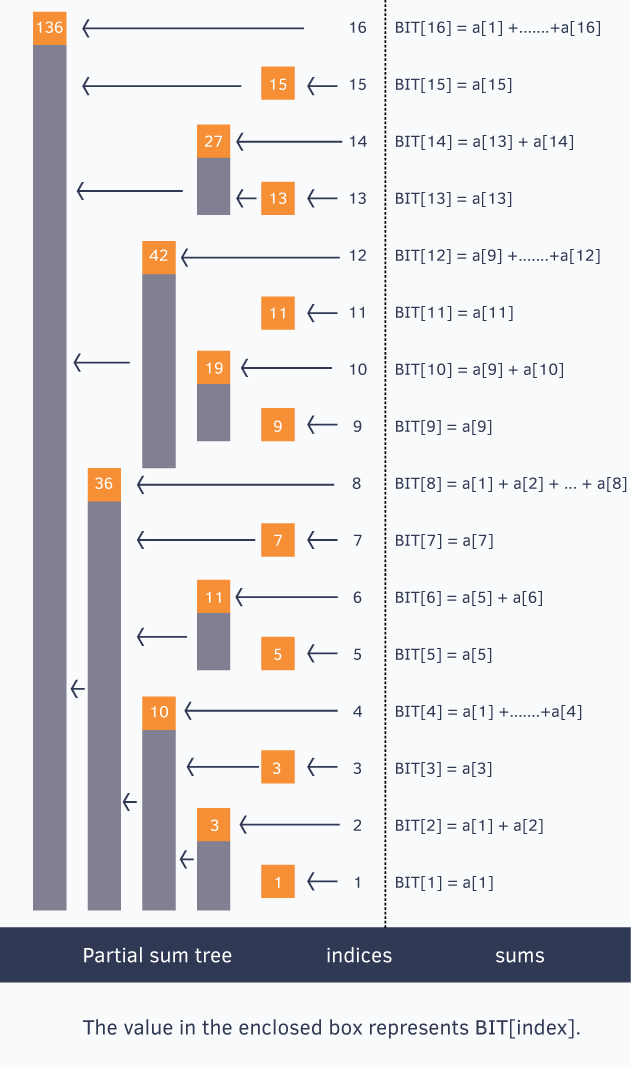
BIT 배열의 각 BIT[i]는 다음과 같은 규칙으로 합을 저장합니다. BIT[i]는 인덱스 i를 포함하여, i에서 LSB를 뺀 값 ()까지의 구간 합을 저장합니다.
를 들어,
- BIT[1]은 A[1]의 값을 저장합니다. (LSB=1)
- BIT[2]은 A[1] + A[2]의 값을 저장합니다. (LSB=2)
- BIT[3]은 A[3]의 값을 저장합니다. (LSB=1)
- BIT[4]은 A[1] + A[2] + A[3] + A[4]의 값을 저장합니다. (LSB=4)
이처럼 각 BIT[i]는 부터 까지의 합을 담당하게 됩니다.
update와 query
Fenwick Tree는 주로 1-based indexing (인덱스를 1부터 시작)으로 구현됩니다.
1. update(idx, val): 특정 인덱스 값 갱신 ()
원본 배열의 arr[idx]에 val을 더할 때 (또는 빼거나 설정할 때), Fenwick Tree의 관련 노드들을 갱신해야 합니다.
- idx부터 시작합니다.
- BIT[idx]에 val을 더합니다.
- idx에 LSB(idx)를 더하여 다음 갱신할 부모 노드의 인덱스로 이동합니다. (idx += (idx & -idx))
- 이 과정을 idx가 배열의 크기 N을 초과할 때까지 반복합니다.
2. query(idx): 1부터 idx까지의 누적 합 계산 ()
arr[1]부터 arr[idx]까지의 합을 계산합니다.
- sum = 0으로 초기화합니다.
- idx부터 시작합니다.
- sum에 BIT[idx]의 값을 더합니다.
- idx에서 LSB(idx)를 빼서 다음 합산할 노드의 인덱스로 이동합니다. (idx -= (idx & -idx))
- 이 과정을 idx가 0이 될 때까지 반복합니다.
3. range_sum(L, R): arr[L]부터 arr[R]까지의 구간 합 ()
이 연산은 query 함수를 이용하면 아주 간단합니다. range_sum(L, R) = query(R) - query(L - 1)
코드 블럭 (Python)
class FenwickTree:
def __init__(self, size):
self.size = size
self.tree = [0] * (size + 1) # 1-based indexing을 위해 size + 1
# 특정 인덱스에 값 추가 (점 갱신)
def update(self, idx, val):
# 1-based indexing으로 변환 (문제에 따라 0-based -> 1-based)
idx += 1
while idx <= self.size:
self.tree[idx] += val
# LSB(idx)를 더하여 다음 갱신할 부모 노드로 이동
idx += (idx & -idx)
# 1부터 idx까지의 누적 합 (누적 합 질의)
def query(self, idx):
# 1-based indexing으로 변환
idx += 1
s = 0
while idx > 0:
s += self.tree[idx]
# LSB(idx)를 빼서 다음 합산할 노드로 이동
idx -= (idx & -idx)
return s
# L부터 R까지의 구간 합 (포함)
def range_sum(self, left, right):
# query 함수가 0-based index를 1-based로 변환하므로,
# range_sum의 left/right는 0-based 그대로 넘겨주면 됩니다.
return self.query(right) - self.query(left - 1)
# --- 사용 예시 ---
if __name__ == "__main__":
arr = [1, 2, 3, 4, 5, 6, 7, 8]
n = len(arr)
ft = FenwickTree(n)
# 초기 배열 값으로 Fenwick Tree 구성 (각 원소를 update 하는 방식으로 구성)
for i in range(n):
ft.update(i, arr[i])
print(f"원본 배열: {arr}")
# 인덱스 0부터 4까지의 합 (1 + 2 + 3 + 4 + 5 = 15)
print(f"Index 0부터 4까지의 누적 합: {ft.query(4)}")
# 인덱스 2의 값을 10으로 변경 (원래 3이었으므로, 7을 더해 10으로 만듦)
print(f"Index 2의 값을 10으로 변경 (원래 3, +7)")
ft.update(2, 7)
# 갱신 후 인덱스 0부터 4까지의 합 (1 + 2 + 10 + 4 + 5 = 22)
print(f"Index 0부터 4까지의 누적 합 (갱신 후): {ft.query(4)}")
# 인덱스 1부터 5까지의 구간 합 (arr[1]~arr[5])
# 갱신 후: arr (가상) = [1, 2, 10, 4, 5, 6, 7, 8]
# arr[1] + arr[2] + arr[3] + arr[4] + arr[5] = 2 + 10 + 4 + 5 + 6 = 27
print(f"Index 1부터 5까지의 구간 합: {ft.range_sum(1, 5)}")
예시) 입력 값이 [2, 1, 4, 5, 7, 8, 13, 24, 1, 3] 일 때.
Fenwick Tree를 사용하기 위해 1-based indexing을 사용하고, 초기 tree 배열은 모두 0으로 초기화한다고 가정합니다. 입력 배열의 크기는 입니다.
Fenwick을 이용해 배열 값을 매기면 다음과 같이 저장됩니다. arr는 기존의 배열 값이고 bit arr는 비트별 연속 합산 결과입니다.
왜 bit arr에는 다음과 같이 저장 될까요?

그이유는 LSB(Least Significant Bit) 연산으로 짝수 인덱스 영역을 제외한 합을 저장하기 때문입니다.
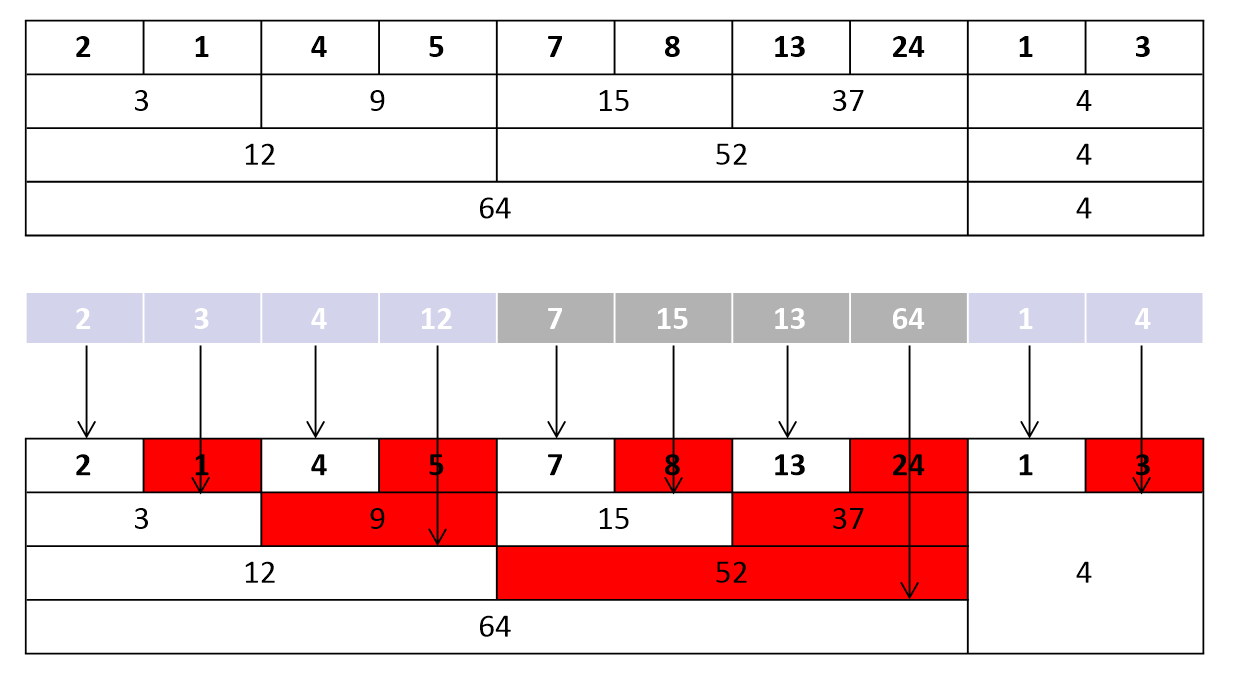
보시는 것 처럼 각 이진수 영역의 합을 저장합니다. 빨간색 영역은 필요 없는 부분입니다. 이렇게 되어서 탐색과 업데이트 시간이 O(N) 에서 O(logN) 만큼 줄어 드는 것입니다. 기존보다 절반만 연산하면 되기 때문입니다.
각 배열마다 상응되는 비트 영역 인덱스와 합을 다음과 같이 구합니다.
1. update(self, idx=0, val=2) (원본 배열의 첫 번째 원소: 0번 인덱스에 2 추가)
- idx += 1: idx는 0 + 1 = 1이 됩니다.
- 첫 번째 반복:
- while idx <= self.size (1 <= 10) 조건이 참입니다.
- self.tree[1] += 2 (현재 self.tree[1]에 2를 더합니다).
- idx += (idx & -idx) 계산:
- idx는 1입니다.
- -idx (1의 2의 보수)는 이진수로 ...1111입니다.
- 1 & -1 (이진수 0001 & ...1111)은 0001 (십진수 1)입니다.
- idx는 1 + 1 = 2가 됩니다.
- 두 번째 반복:
- while idx <= self.size (2 <= 10) 조건이 참입니다.
- self.tree[2] += 2 (현재 self.tree[2]에 2를 더합니다).
- idx += (idx & -idx) 계산:
- idx는 2 (이진수 0010)입니다.
- -idx는 (이진수 1110)입니다.
- 2 & -2 (이진수 0010 & 1110)는 0010 (십진수 2)입니다.
- idx는 2 + 2 = 4가 됩니다.
- 세 번째 반복:
- while idx <= self.size (4 <= 10) 조건이 참입니다.
- self.tree[4] += 2 (현재 self.tree[4]에 2를 더합니다).
- idx += (idx & -idx) 계산:
- idx는 4 (이진수 0100)입니다.
- -idx는 (이진수 1100)입니다.
- 4 & -4 (이진수 0100 & 1100)는 0100 (십진수 4)입니다.
- idx는 4 + 4 = 8이 됩니다.
- 네 번째 반복:
- while idx <= self.size (8 <= 10) 조건이 참입니다.
- self.tree[8] += 2 (현재 self.tree[8]에 2를 더합니다).
- idx += (idx & -idx) 계산:
- idx는 8 (이진수 1000)입니다.
- -idx는 (이진수 1000)입니다.
- 8 & -8 (이진수 1000 & 1000)는 1000 (십진수 8)입니다.
- idx는 8 + 8 = 16이 됩니다.
- 다섯 번째 반복:
- while idx <= self.size (16 <= 10) 조건이 거짓이므로 루프가 종료됩니다
2. update(self, idx=1, val=1) (원본 배열의 두 번째 원소: 1번 인덱스에 1 추가)
-
- idx += 1: idx는 1 + 1 = 2가 됩니다.
- 첫 번째 반복:
- while idx <= self.size (2 <= 10) 조건이 참입니다.
- self.tree[2] += 1 (현재 self.tree[2]에 1을 더합니다).
- idx는 2 + (2 & -2) = 2 + 2 = 4가 됩니다.
- 두 번째 반복:
- while idx <= self.size (4 <= 10) 조건이 참입니다.
- self.tree[4] += 1 (현재 self.tree[4]에 1을 더합니다).
- idx는 4 + (4 & -4) = 4 + 4 = 8이 됩니다.
- 세 번째 반복:
- while idx <= self.size (8 <= 10) 조건이 참입니다.
- self.tree[8] += 1 (현재 self.tree[8]에 1을 더합니다).
- idx는 8 + (8 & -8) = 8 + 8 = 16이 됩니다.
- 네 번째 반복:
- while idx <= self.size (16 <= 10) 조건이 거짓이므로 루프가 종료됩니다.
3. update(self, idx=2, val=4) (원본 배열의 세 번째 원소: 2번 인덱스에 4 추가)
- idx += 1: idx는 2 + 1 = 3이 됩니다.
- 첫 번째 반복:
- while idx <= self.size (3 <= 10) 조건이 참입니다.
- self.tree[3] += 4 (현재 self.tree[3]에 4를 더합니다).
- idx += (idx & -idx) 계산: idx는 3 (이진수 0011). -idx는 1101. 3 & -3은 0001 (십진수 1)입니다. idx는 3 + 1 = 4가 됩니다.
- 두 번째 반복:
- while idx <= self.size (4 <= 10) 조건이 참입니다.
- self.tree[4] += 4 (현재 self.tree[4]에 4를 더합니다).
- idx는 4 + (4 & -4) = 4 + 4 = 8이 됩니다.
- 세 번째 반복:
- while idx <= self.size (8 <= 10) 조건이 참입니다.
- self.tree[8] += 4 (현재 self.tree[8]에 4를 더합니다).
- idx는 8 + (8 & -8) = 8 + 8 = 16이 됩니다.
- 네 번째 반복:
- while idx <= self.size (16 <= 10) 조건이 거짓이므로 루프가 종료됩니다.
4. update(self, idx=3, val=5) (원본 배열의 네 번째 원소: 3번 인덱스에 5 추가)
- idx += 1: idx는 3 + 1 = 4가 됩니다.
- 첫 번째 반복:
- while idx <= self.size (4 <= 10) 조건이 참입니다.
- self.tree[4] += 5 (현재 self.tree[4]에 5를 더합니다).
- idx는 4 + (4 & -4) = 4 + 4 = 8이 됩니다.
- 두 번째 반복:
- while idx <= self.size (8 <= 10) 조건이 참입니다.
- self.tree[8] += 5 (현재 self.tree[8]에 5를 더합니다).
- idx는 8 + (8 & -8) = 8 + 8 = 16이 됩니다.
- 세 번째 반복:
- while idx <= self.size (16 <= 10) 조건이 거짓이므로 루프가 종료됩니다.
이런식으로 반복적으로 열번째 배열까지 다 끝나춰 줍니다.
그러면 나중에 탐색이나 수정 할 때, 이진트리형식으로 업데이트와 탐색만 해주면 O(logN) 만큼만 할 수가 있게 됩니다.
'알고리즘' 카테고리의 다른 글
| Knapsack (Greedy, 0/1) 알고리즘 정리 (3) | 2025.08.29 |
|---|---|
| 최소 연결 그래프 - Minimum Spanning Tree (MST) (1) | 2025.08.19 |
| 음수를 가진 최적경로 탐색 - 벨만포드(Bellman ford) 알고리즘 정리 (5) | 2025.08.17 |
| Ford-Fulkerson & Edmons-Karp 알고리즘 (3) | 2025.08.16 |
| Topological Sort란? Kahn's Algorithm으로 DAG 정렬 쉽게 이해하기 (0) | 2025.06.01 |


